
Сегодня поделюсь деталями того, как устроена работа ИИ-агента по имени “Виктор” для предоставления поддержки пользователям нашего проекта “Кассовая программа GBS.Market“.
И так, задача, которую решаем — реализация бота поддержки на базе искусственного интеллекта, а именно Chat.GPT в связке с ПланФикс. Что умеет такой бот:
- отвечать на текстовые сообщения пользователей
- преобразовывать голосовые сообщения пользователя и давать ответ текстом
- распознавать присланные изображения/скриншоты и давать ответ, учитывая содержимое изображения
- отвечать в рамках знаний о нашем продукте (кассовая программа GBS.Market)
- сохранять контекст (не терять мысль диалога)
Собираем сообщения в ПланФикс
Начнем с самого начала, когда пользователь решает обратиться в службу поддержки. У нас есть несколько каналов поддержки, но в рамках задачи нам интересны те, где обычно подразумевается “живой” диалог (чаты), это соц.сети и мессенджеры. В нашем случае это:
- Телеграм
- Viber
- Вконтакте
Все сообщения из чатов этих “сетей” собираются в одном месте – ПланФиксе.
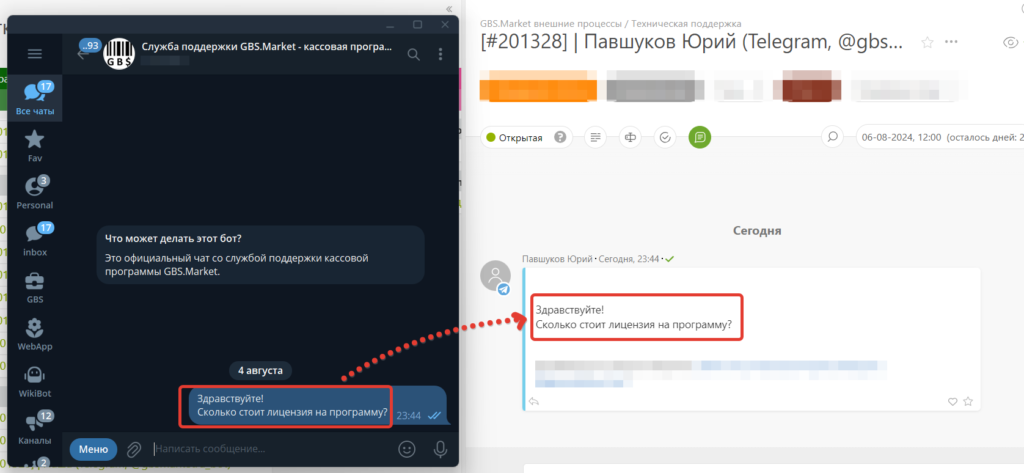
ПланФикс – это мощный сервис, который можно использовать в т.ч. как хэлпдеск, т.е. для оказания поддержки пользователей. Так вот, когда пользователь пишет, например, через Телеграм, то его сообщение прилетает нам в ПланФикс, где мы можем ответить или настроить какую-то дополнительную логику: автоответы, парсинг сообщений, подключение определенных сотрудников и многое другое.
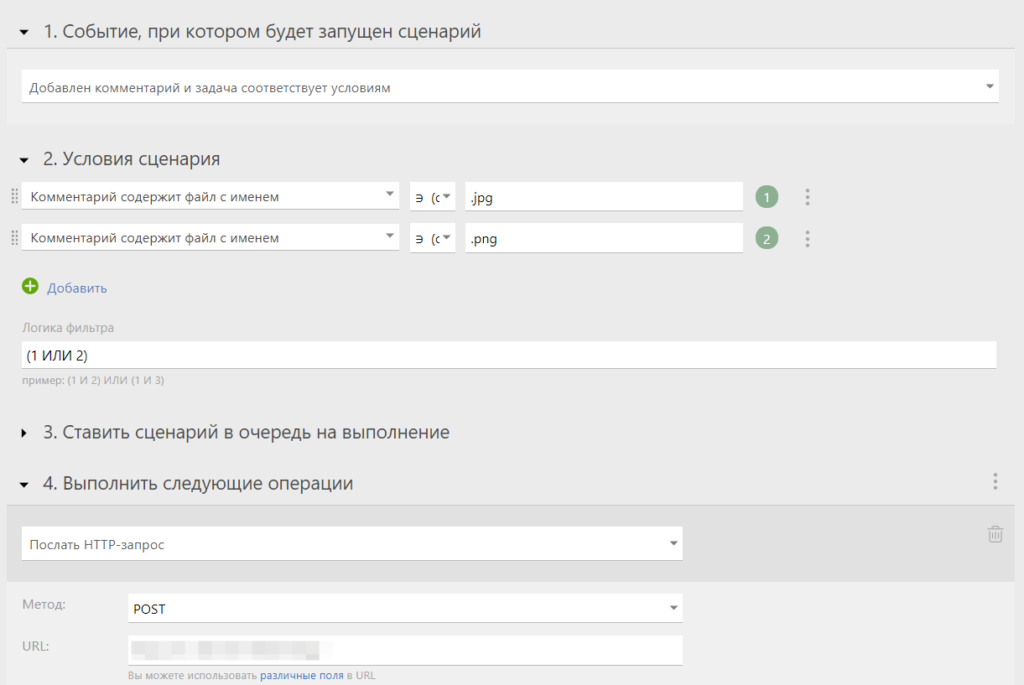
В ПланФиксе есть такая вещь как “сценарии”, которые позволяют в режиме no-code настроить алгоритм работы с пришедшем сообщением. Событие, на которое мы будем реагировать – это новый комментарий (сообщение) от пользователя.
Поднимаем сервер под скрипты
В текущих реалиях, к сожалению, доступа к Chat.GPT из России нет. Поэтому, чтобы вся “магия” работала, нам потребуется промежуточный сервер в другой локации. Задача сервера — перенаправлять запросы, отправленные к нему, к openai api.
Скрипты написаны на python. Собственно, чтобы запустить все это на сервере, нужно обеспечить соответсвующее окружение: ubuntu + nginx + flask + gunicorn. При желании легко нагуглить (или попросить Chat.GPT) как на python сделать свой веб-сервис с api. Кстати, сами скрипты можно попросить написать Chat.GPT, но однозначно стоит изучить документацию по api openai, чтобы заставить все это работать.
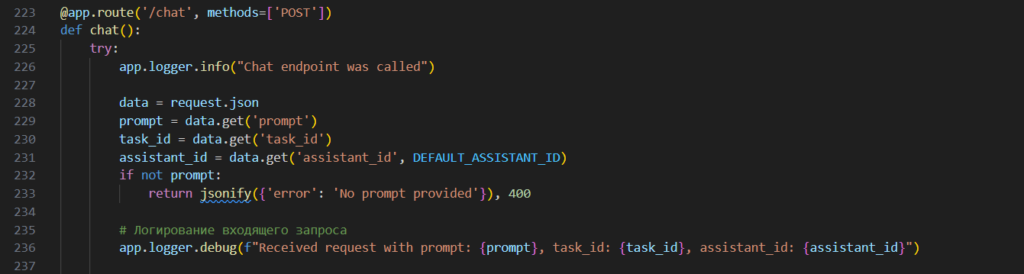
Суть скриптов такая: получаем запрос (вопрос) и отправляет его по API в Chat.GPT к заранее настроенному ассистенту, которому “скормлена” база знаний и прописан системный промпт (инструкция). Скрипт получает ответ от ИИ и возвращает его туда, откуда пришел запрос.
Кода в общей сложности на 300-500 строк. При наличии опыта поднять, настроит сервер и прописать логику можно за одну ночь.
Идем дальше.
Загрузка знаний
Т.к. вопросы, поступающие от наших пользователей, очень специфичны, то Chat.GPT не может дать на них внятные ответы, несмотря на то, что он прочитал почти весь интернет. В этом случае необходимо дообучить ИИ на наших данных.
Мы не используем файн-тюнинг модели, а сделали иначе — загружаем “знания” в виде markdown-документов в Vector Store (векторное хранилище), подключенный к ассистенту. Загрузка таких знаний у нас автоматизирована (на том же питоне):
- скармливаем скрипту sitemap (карту сайт) базы знаний в xml формате
- скрипт проходит по всем страницам и сохраняет в файлы в markdown-формате
- очищаем в vector store старые данные
- загружаем актуальные знания
При этом в каждый markdow-документ добавляем примечание, что содержимое этого документа доступно по определенному url, чтобы ИИ-бот смог добавить к ответу что-то вроде “Подробнее в статье” с указанием валидного адреса.
Используется модель “4omni”, которая отлично справляется с поставленными задачами. Если хочется чуть сэкономить, можно попробовать “4o-mini”.
Расшифровка голосовых сообщений
Пользователи любят “голосовухи” настолько сильно, насколько бизнес-сообщество их ненавидит. С голосовыми сообщениями работать неудобно и некомфортно. Чтобы ИИ мог отвечать и на них — надо преобразовать в текст. Тут магии куда меньше — технологии STT (speech-to-text) известны до эпохи чатаджипити.
В нашем случае неплохо справляется Yandex.Cloud, для взаимодействия с которым тоже написан небольшой скрипт.
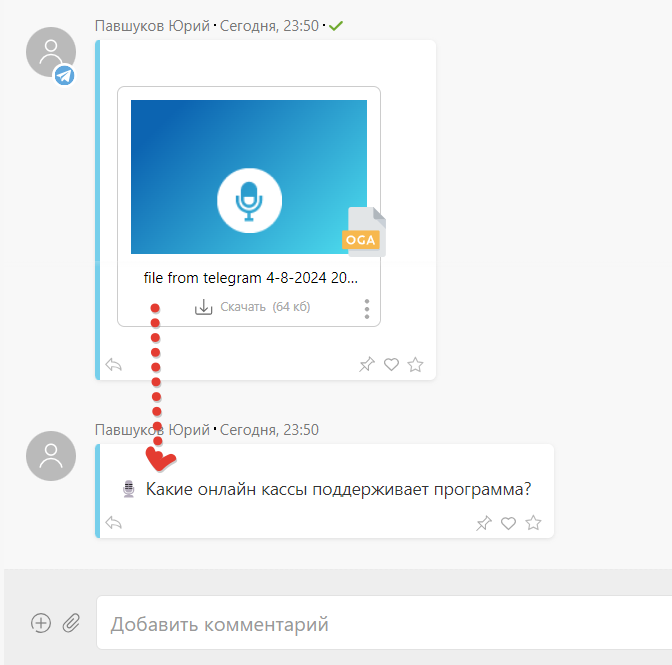
В ПланФиксе это выглядит так, будто бы пользователь сам написал текстом свое голосовое сообщение.
Чтобы это сработало – ловим сценарием событие “новый комментарий” и проверяем, что добавлен файл с расширением звукового файла.
Распознавание изображений
Вишенкой на торте, которую мы буквально сегодня добавили к работе Виктора, — это возможность “понимать” что за картинку отправляет пользователь. Чаще всего — там скриншот или фото экрана с интерфейсом программы или сообщением об ошибке.
Для работы с картинками взаимодействуем с Chat.GPT, который кратенько описывает то, что видит на изображении. Если там ошибка — присылает в ответ ее текст. Тут используется модель “4o-mini”, она дешевле, а справляется с расшифровкой отлично. Сторонние знания, кстати, ей тут не нужны.
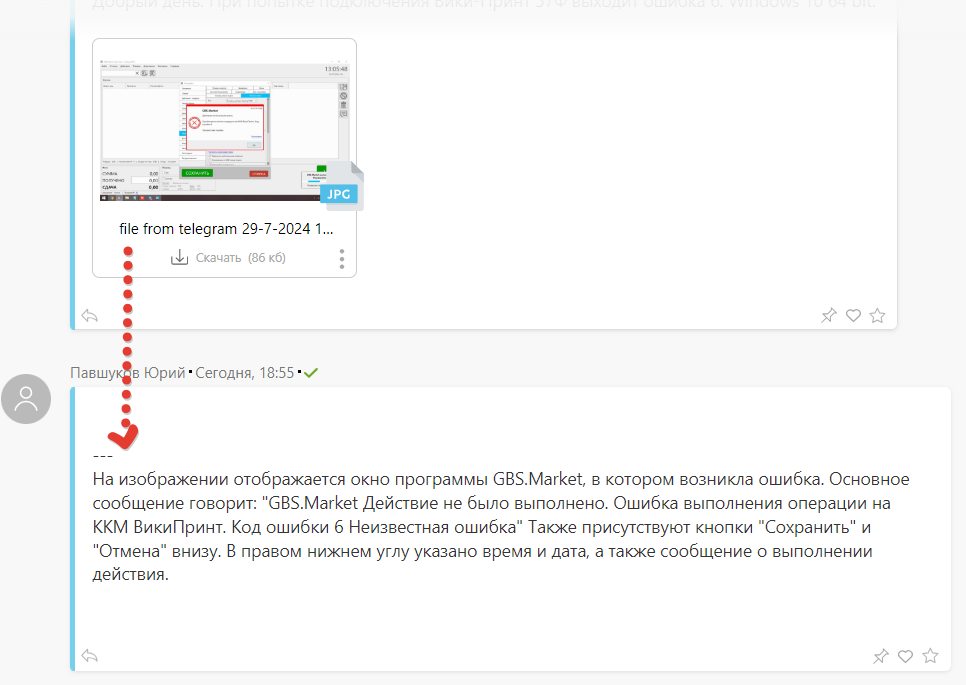
В ПланФиксе сообщение с описанием изображения, как и с голосовым, будет от имени пользователя – будто бы он сам описал картинку.
Тут сценарий работает по аналогии с голосовыми – но проверяем по расширению на наличие картинки.
Буфер сообщений
Когда все компоненты готовы к работе, возвращаемся к ПланФиксу, где нас ждут сообщения от пользователей.
И так, пользователь пишет в телеграм:
- Добрый день!
- Сколько стоит?
- Как купить?
- А будет работать с кассой АТОЛ?
- …
Все эти сообщения друг за другом за короткий промежуток времени. Думаю, знакомая многим картина. Если мы будем каждое сообщение отправлять по отдельности, то диалог не получится красивым. Несмотря на то, что ИИ отвечает быстро, — это не происходит молниеносно. И может случиться так, что пользователь добавил второе сообщение, а мы следом отправили только ответ на первое. Пока готовим ответ на второе — пользователь пришлет третье.
К тому же, мы с помощью ИИ пытаем “эмулировать” работу человека. Решение — не отвечать мгновенно, а чуть-чуть подождать, пока пользователь прекратит писать. И тут начинает работу первый сценарий в ПланФикс, который аккуратно складывает все сообщения в специально предназначенное поле.
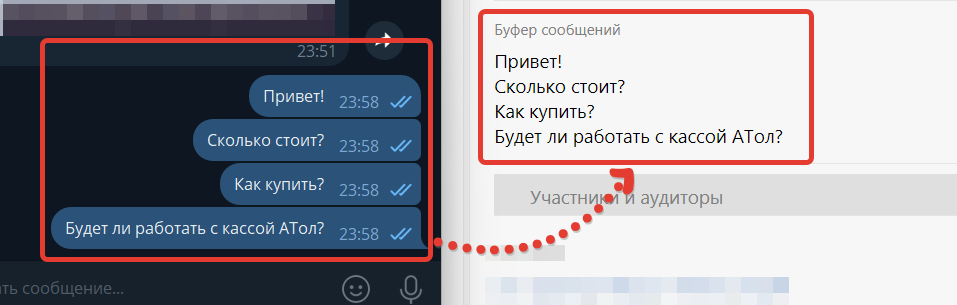
При этом голосовые сообщения и картинки, которые мы превратили в текст, будут аналогично добавляться в буфер.
Вжух!
Последний взмах волшебной палочки сценарий в цепочке: ждем минуту с последнего комментария в задаче и отправляем накопленное в поле “буфер” нашему основному скрипту, который перешлет запрос к ИИ и вернет ответ. Скрипт вычленит ответ и отправит его пользователю.
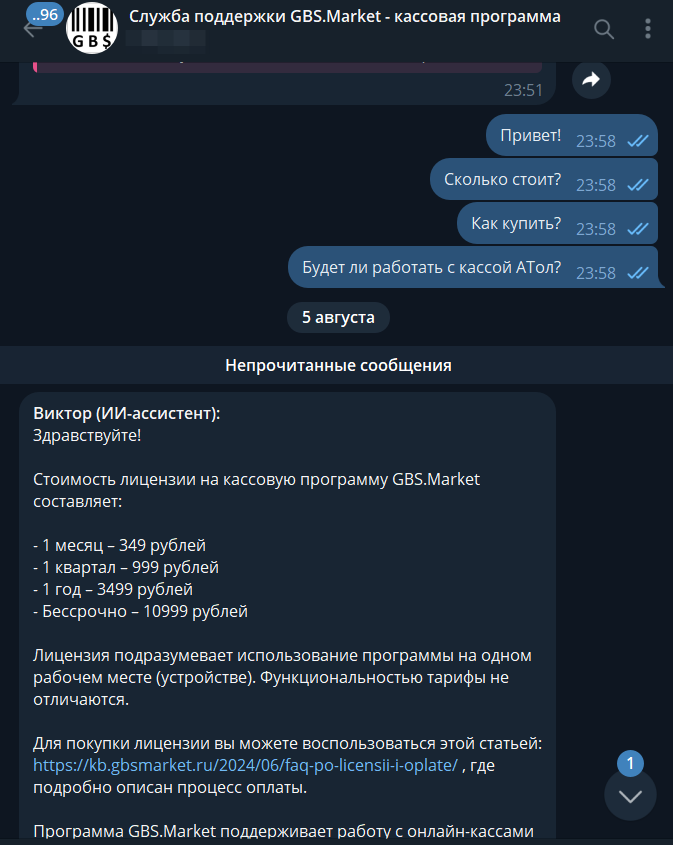
Аналитика
В ПланФиксе (для тех, кто с ним мало знаком) есть такая сущность, как “аналитика”, некое подобие баз данных с настраиваемыми полями. Так вот при получении ответа от ИИ мы добавляем вместе с комментарием еще и аналитику, чтобы в последствии построить отчет с вопросами/ответами и принять действия:
- исправить системный промпт
- исправить статьи базы знаний
- добавить новые материалы в базу знаний
Сохранение контекста
Как показал опыт, сохранение контекста, т.е. истории предыдущего общения — это важный момент, т.к. пользователь первый вопрос задать развернуто, а вторым спросить что-то уточняющее. Если не запомнить первый вопрос, то ответ на второй скорее, вероятно, будет неадекватным.
Поэтому одна из задач, решаемых скриптами на сервере, — это работа в рамках одного чата с ИИ для одной задачи в ПланФиксе. Для этого скрипт сохраняет номер задачи и связанный с ней ид чата, а потом использует тот же идентификатор чата, если вопрос пришел из уже “знакомой” задачи.
Заключение
Уже сегодня часть обращений, поступающим к нам, полностью закрываются ИИ-агентом без вмешательства человека. Конечно, каждый ответ нейросети в последствии анализируется, но большинство из ответов достаточно качественные и четко структурированные. При необходимости ИИ может позвать сотрудника. Или сотрудник может вмешаться в диалог, когда ИИ ошибается.
Из плюсов, что я вижу в использовании ИИ в подобном сценарии:
- работа 24/7 без обеда и выходных
- высокая скорость поиска необходимой информации
- быстрая подготовка структурированного ответа
- строгое следование прописанным инструкциям
Кроме того, мы уделяем внимание анализу ответов и чуть ли не ежедневно наполняем базу знаний, что положительно сказывается на работе как ИИ-агента, так и живых сотрудников поддержки.
Конечно, пока что ИИ не покрывает полностью все вопросы, причиной тому:
- отсутствие необходимой информации в базе знаний
- очень размытая формулировка вопроса пользователя, когда только по наитию можно понять смысл
- специфичные задачи, которые (пока) может решить только человек, например, анализ логов или базы данных
Сегодня нейросеть не способна заменить опытного сотрудника поддержки, но по собственному опыту могу сказать, что ответы ИИ могут быть лучше новичка на первой линии поддержки. Конечно, если для ответов есть хорошо проработанная база знаний.